
Overview
The Word Analyzer project leverages the Word2Vec model to analyze the relationships between words in the English language. It allows users to explore word similarities and relationships, making it an engaging tool to understand language better.
How Does It Work?
The system works in three main steps:
- Input: The user enters a word or two words to find their nearest words or similarity score.
- Processing: The Word2Vec model processes the input, converting words into numerical vectors.
- Output: The system provides the nearest words or the similarity score based on vector calculations.
Key Concepts
Vectorization
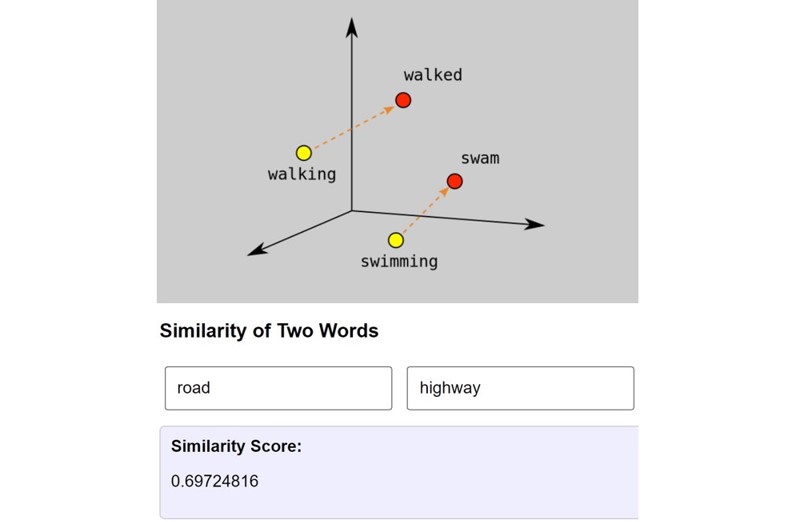
Vectorization is the process of converting words into numerical representations (vectors). In Word2Vec, each word is represented as a point in a high-dimensional space. Words with similar meanings are placed closer together.
Similarity Score
The similarity score measures how closely two words are related based on their vector positions. A score closer to 1 indicates higher similarity, while a score closer to -1 indicates less similarity.
Cosine Distance
Cosine distance calculates the angle between two word vectors. Smaller angles indicate higher similarity, while larger angles indicate less similarity. This method helps measure the relationship between words effectively.
Features
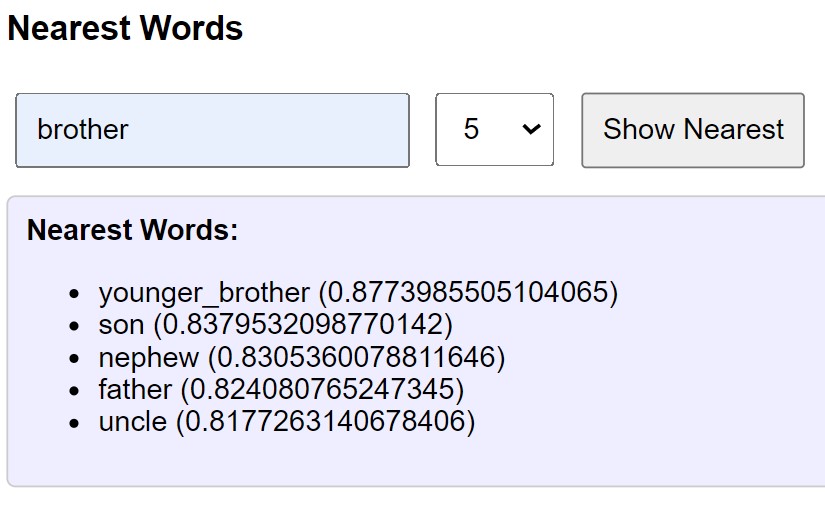
- Finds the nearest words to a given word.
- Calculates the similarity score between two words.
- Leverages the Google News Word2Vec model for word analysis.
- Interactive and user-friendly interface for exploring language relationships.
Limitations
- The model is limited to the vocabulary it was trained on and may not recognize new or uncommon words.
- Similarity scores rely on vector representations and may not capture subtle differences in word meanings.